DeepSeek-V3论文
1. 概述
- DeepSeek-V3采用MoE架构,总共
671B参数,每个token会激活37B参数量;训练采用了14.8T Token数,训练耗时为2.788M H800 GPU时 - 跟DeepSeek-V2相同点
- MLA(
Multi-head Latent Attention) - DeepSeekMoE结构
- MLA(
- 跟DeepSeek-V2不同点
- 负载均衡策略: 使用auxiliary-loss-free策略用于负载均衡,减少不均衡对模型性能产生负面影响
- 训练目标:使用了多token预测目标(
Multi-Token Prediction),简称MTP
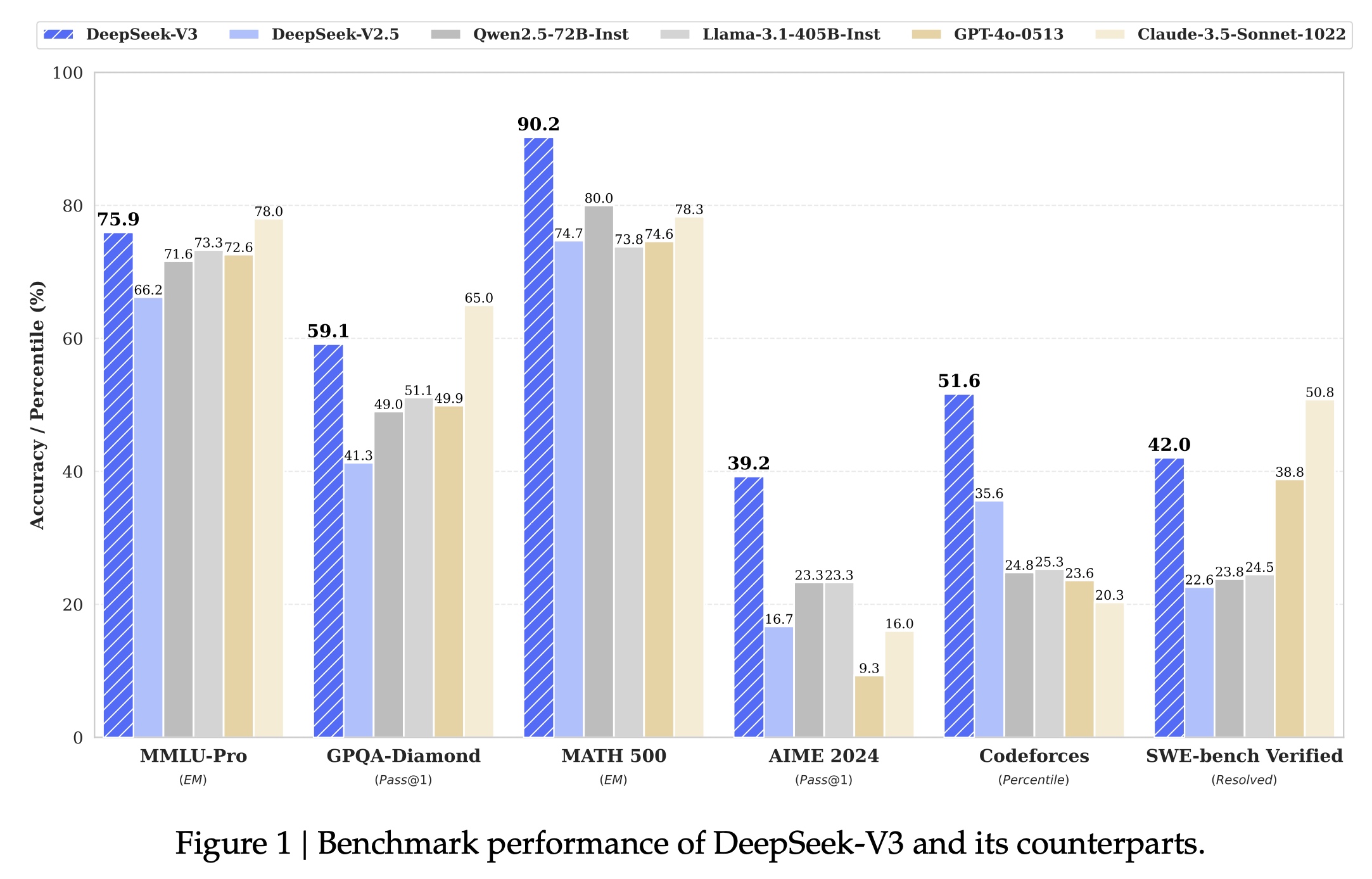
- 各个评测集下的效果:
2. 模型算法
2.1 DeepSeek-V3基础架构
复用了MLA与DeepSeekMoE的模型结构
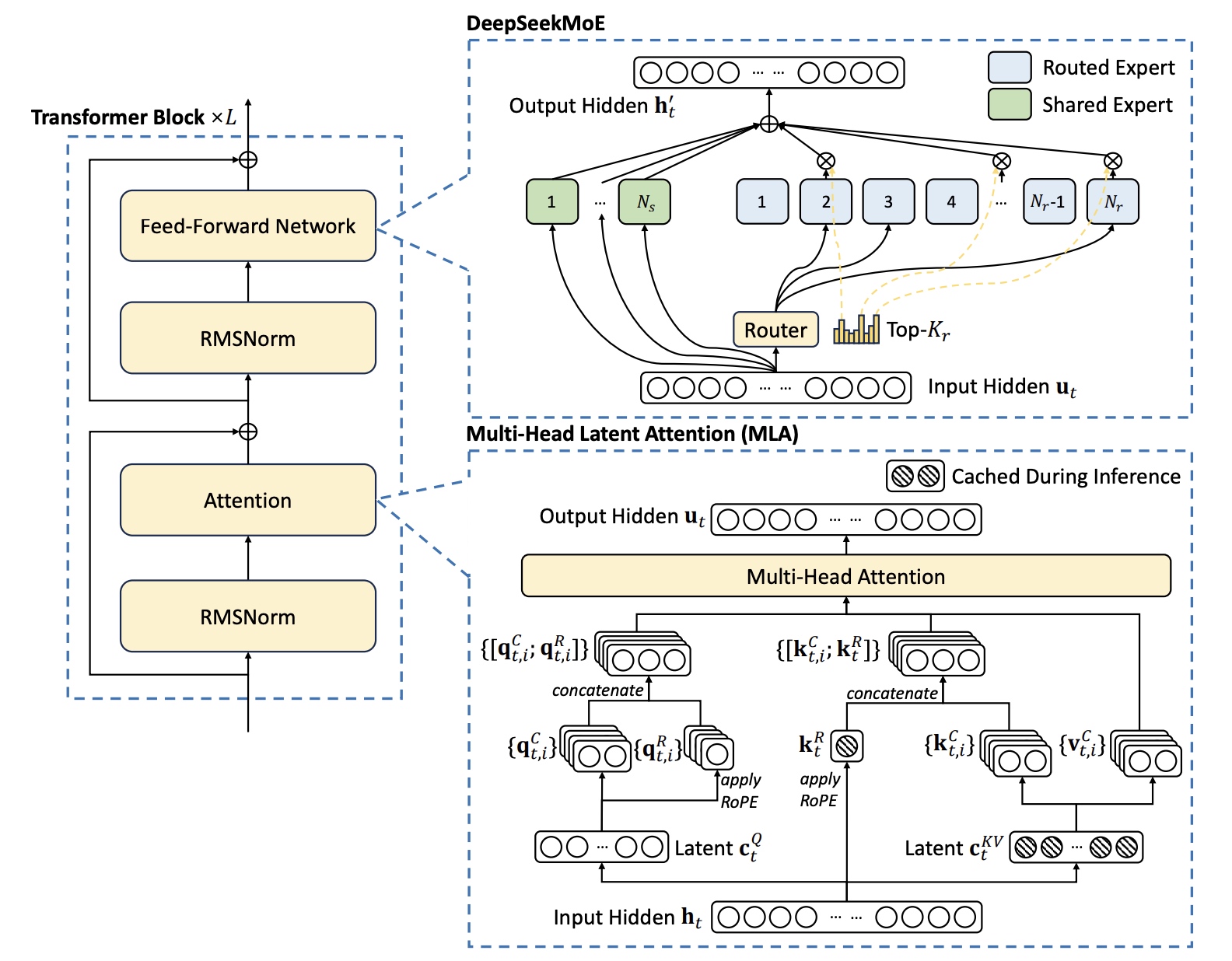
2.2 Multi-Head Latent Attention(MLA)
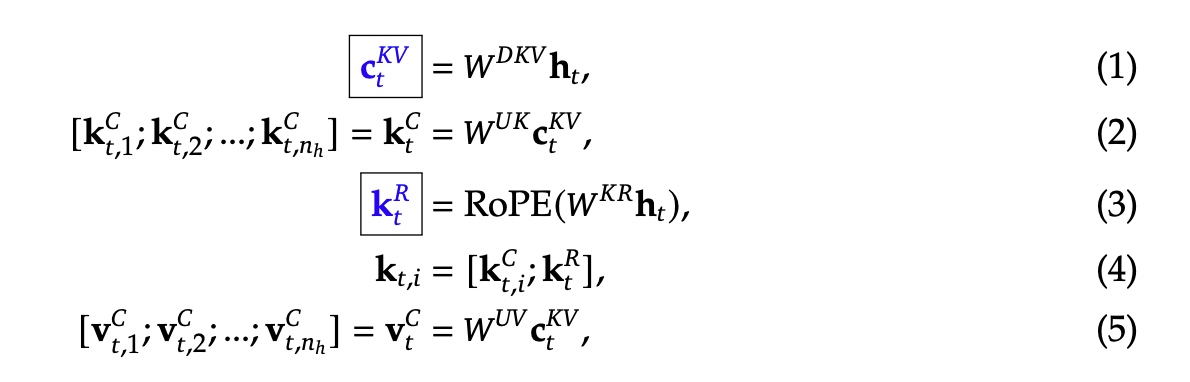
对于key和value进行了低秩的压缩操作。公式如上,其中\(d\) 表示embedding层的维度,\(n_h\) 表示attention head头的个数, \(d_h\) 表示每个head的维度,\(\mathbf{h}_t \in \mathbf{R}^d\) 表示第 \(t\) 个token对应的attention输入。\(\mathbf{c}_t^{KV} \in \mathbf{R}^{d_c}\) 是对于key和value压缩的隐向量;\(d_c(<< d_h n_h)\) 表示KV压缩的维度;\(W^{DKV} \in \mathbf{R}^{d_c \times d}\) 表示下映射矩阵,\(W^{UK}, W^{UV} \in \mathbf{R}^{d_c n_h \times d_c}\) 是对应key和value的上映射矩阵;\(W^{KR} \in \mathbf{R}^{d_h^R \times d}\) 是用于产生RoPE用的解耦key的矩阵;\(RoPE(\cdot)\) 表示RoPE操作; \([\cdot;\cdot]\) 表示拼接操作;对于MLA来说只有框住的蓝色变量会在生成时被cache住。
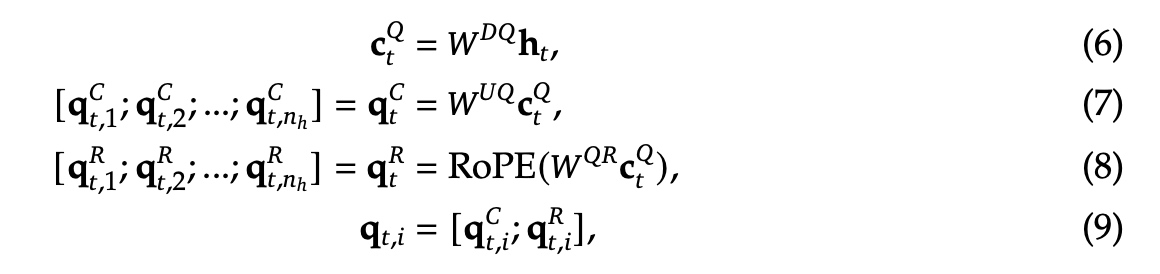
对于query来说也可以进行低秩的压缩操作,公式如上。其中 \(c_t^Q\) 表示用于压缩query的隐向量;\(d'_c(<< d_h n_h)\) 表示query压缩的维度,\(W^{DQ} \in \mathbf{R}^{d'_c \times d}, W^{UQ} \in \mathbf{R}^{d_h n_h \times d'_c}\) 分别是query的下映射矩阵与上映射矩阵。\(W^{QR} \in \mathbf{R}^{d_h^R n_h \times d'_c}\) 表示用于生成RoPE解耦query的矩阵。
最终query(\(\mathbf{q}_{t,i}\)), key(\(\mathbf{k}_{j,i}\)), values(\(\mathbf{v}_{j,i}^C\))会一起计算出来最终结果 \(\mathbf{u}_t\), \(W^O \in \mathbf{R}^{d \times d_h n_h}\) 表示输出的映射矩阵。

2.3 无负载均衡loss策略的DeepSeekMoE
DeepSeekMoE基础架构:如下,\(\mathbf{u}_t\) 是第t个token的FFN输入,\(\mathbf{h}'_t\) 是表示FFN的输出。
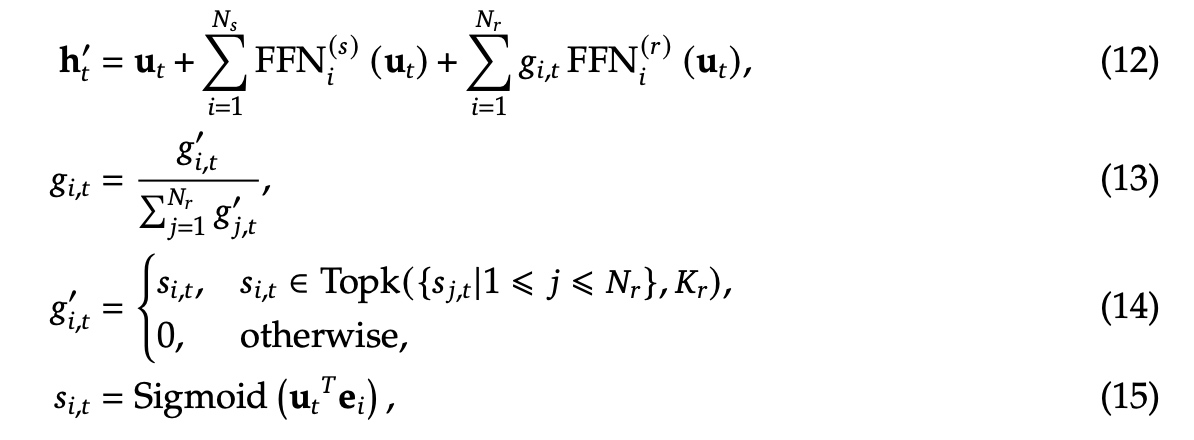
\(N_s, N_r\) 分别表示共享专家与路由专家的个数,\(FFN_i^{(s)} (\cdot), FFN_i^{(r)}(\cdot)\) 分别表示第i个共享专家与第i个路由专家;\(K_r\) 表示被激活专家的个数;\(g_{i,t}\) 表示第i个专家的门控值;\(s_{i,t}\) 表示token到专家的仿射值;\(\mathbf{e}_i\) 表示第i个路由expert的中心向量。
无负载均衡loss策略:辅助负载均衡loss对于性能会有影响,为了实现性能与负载均衡的权衡,使用了无负载均衡loss策略,对每个expert加了一个 \(b_i\) 的bias参数,一起加到了 \(s_{i,t}\) 中,\(i\) 表示第i个expert; \(\gamma\) 是一个超参系数,在每个step结束后,如果专家处理的token量过载,bias值会按 \(\gamma\) 系数减少,反之会对应增加。
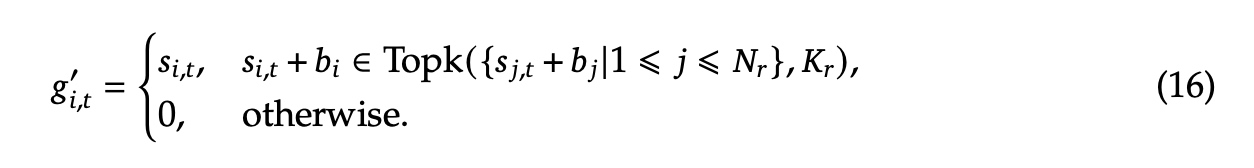
sequence感知辅助loss:为了避免单个sequence可能存在的极度不平衡,增加了sequence感知的辅助loss,\(\alpha\) 是超参系数,这个 \(\mathcal{L}_{Bal}\) 序列平衡损失旨在促使每个序列上的专家负载达到平衡。
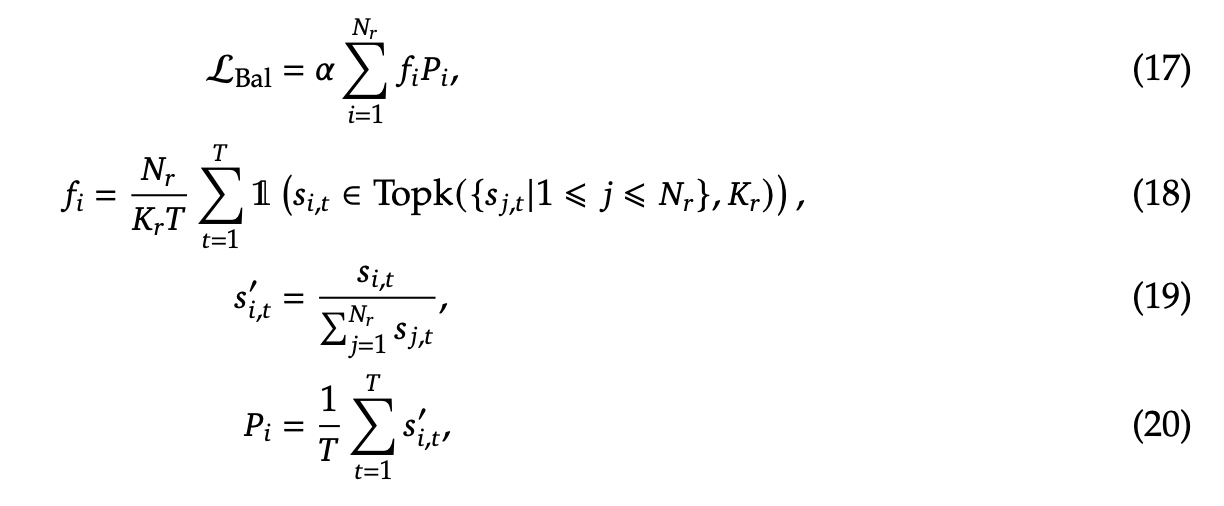
限制结点的路由策略:DeepSeek-V3跟DeepSeek-V2类似,每个token最多发给 \(M\) 个node, 根据分发到node节点上的最高的映射值( \(\frac{K_r}{M}\) )求和来决定。这样可以实现计算与通信的完全掩盖。
不用丢弃token:DeepSeek-V3可以保持比较好的负载均衡,所以训练和推理过程中不用丢弃token。
2.4 多token预测(Multi-Token Prediction (MTP))
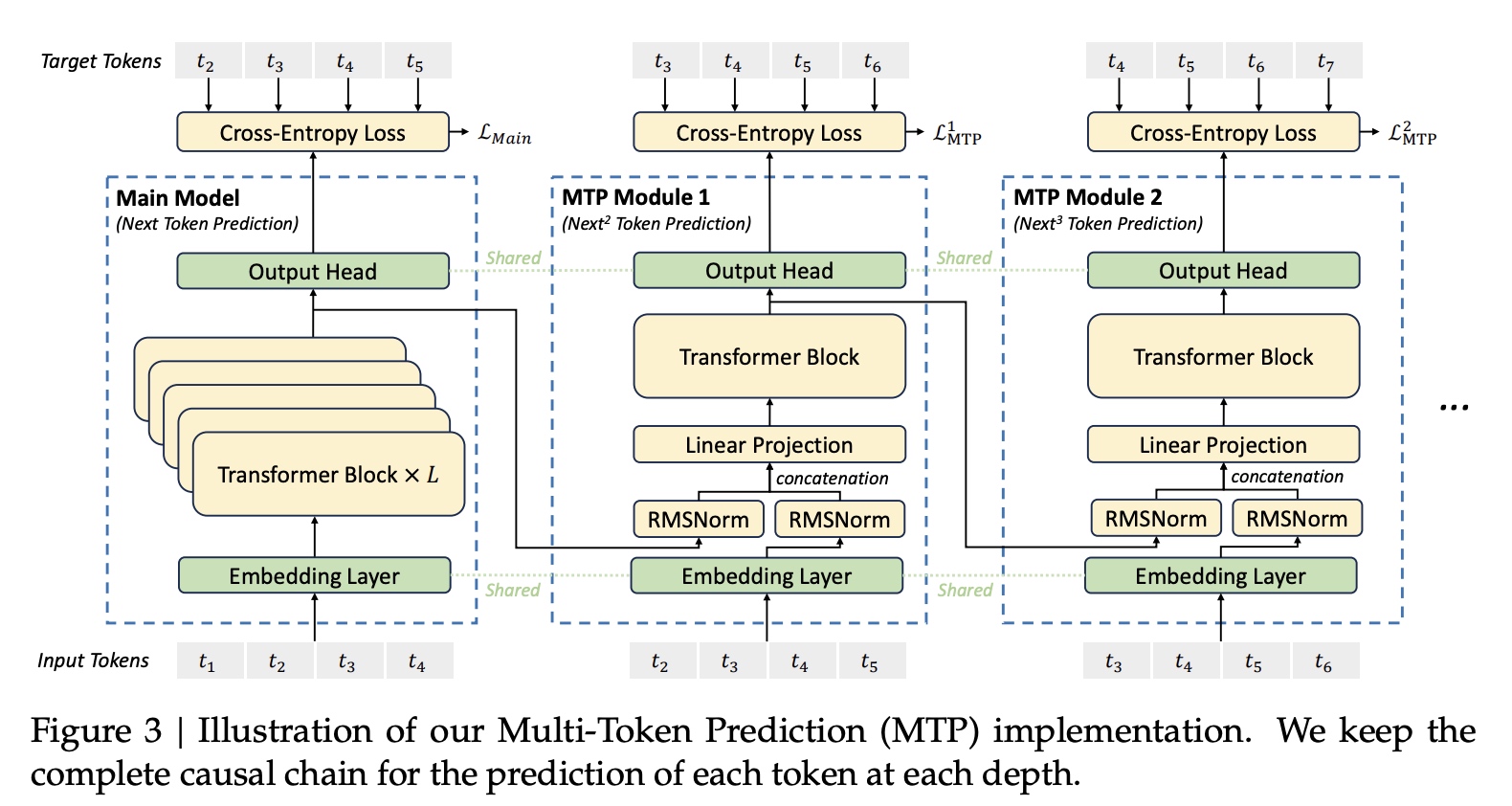
MTP组网使用了 \(D\) 个连续的MTP模块同时预测 \(D\) 个输出token, 第 \(k\) 个MTP模块中由一个共享的embedding模块(\(Emb(\cdot)\))、一个共享的输出模块(\(OutHead(\cdot)\))、一个Transformer块(\(TRM_k(\cdot)\))、以及一个线性映射矩阵(\(M_k \in \mathbf{R}^{d \times 2d}\))组成。
对于第i个输入token(\(t_i\)), 在第
\(k\) 层深度的预测来说,我们会先将
\(t_i\) 在 \(k-1\) 层模块的输出(\(\mathbf{h}_i^{k-1} \in \mathbf{R}^d\))与第
\(i+k\) 个token的embedding向量(\(Emb(t_{i+k} \in
\mathbf{R}^d)\))进行拼接操作,然后使用线性乘法(Linear Projection)进行处理。当k=1时,\(\mathbf{h}_i^{k-1}\) 是main
model模块的表示。
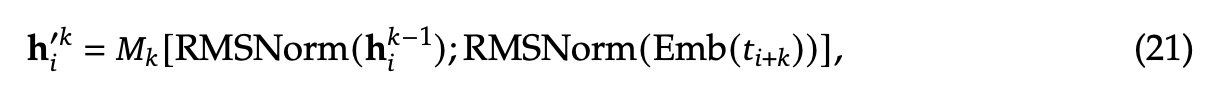
拼接后的 \(h_i^{'k}\) 作为第
\(k\)
个Transformer Block的输入,计算出当前的Transformer Block的输出(\(\mathbf{h}_i^k\)). \(T\) 表示输入sequence的总长度,

最终使用 \(\mathbf{h}^k_i\)
作为共享的 Output Head 的输入,
计算第k个token的预测输出的概率分布 \(P_{i+1+k}^k \in \mathbf{R}^V\) , \(V\) 是词表大小。

MTP训练目标会计算loss(\(\mathcal{L}^k_{MTP}\)), T表示sequence长度,\(t_i\) 表示第i个位置的真实值, \(P_i^k[t_i]\) 表示 \(t_i\) 在第k个MTP模块的预测概率,最终计算一个平均的MTP loss值,\(\lambda\) 是权重的因子。
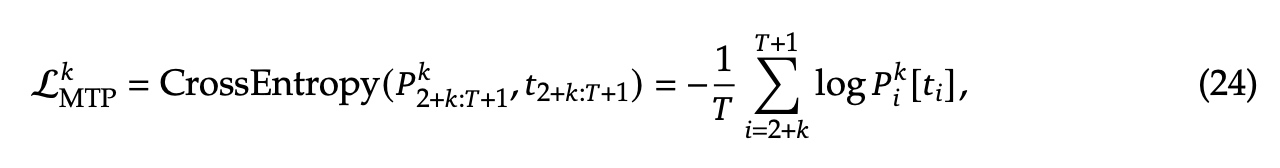
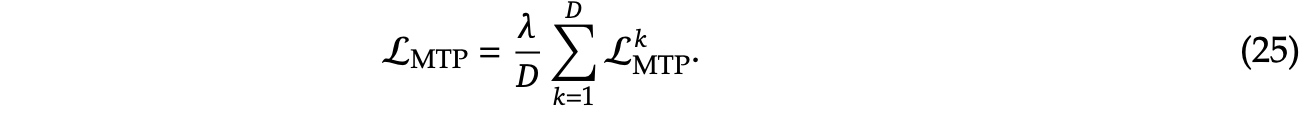
3. 工程实现
DeepSeek-V3使用2048块H800卡训练,训练过程中流水线并行度(PP)为16;专家并行度(EP)为64, 涉及8个node节点;DP并行打开了ZeRO-1。在PP并行过程中采用了DualPipe的流水线并行算法减少气泡。优化了训练显存占用,使得训练过程中没有使用Tensor并行。
3.1 DualPipe并行
DualPipe并行的核心是计算与通信过程的掩盖,过程分被分解为前反向多个chunk来进行掩盖。每个chunk包含有四个部分:attention,
all-to-all dispatch,
MLP和all-to-all combine。类似ZeroBubble算法一样,对于attention和mlp来说,反向中会被拆为两个部分:backward for input
和 backward for weights。另外增加了PP通信的chunk,
在下图中,调整了GPU
SMs用于通信和计算的比例,使得all-to-all与PP通信可以被完全掩盖。橙色表示前向,绿色表示backward for input,
蓝色表示backward for weights,紫色表示PP通信,红色表示barrier.

基于上述通信计算掩盖的策略,实现了一个双向的流水线PP并行调度(DualPipe),下图中PP并行涉及的rank数为8个,PP并行度为8,这里的Dual表示两组PP并行,一组是从dev0->dev1->dev2->...->dev7, 另外一组是从dev7->dev6->dev5->...->dev0.

不同PP并行方法对比如下,F是前向chunk执行时间,B是反向chunk执行时间,W是backward for weights
的chunk,
F&B是两个手动掩盖的前向与反向chunk。峰值的activation大小增加 \(\frac{1}{PP}\) 倍.
尽管PP需要两倍的Parameter参数量,但是由于EP并行度很大,增加不了太多的显存。DualPipe要求PP并行度与micro-batch数被2整除。
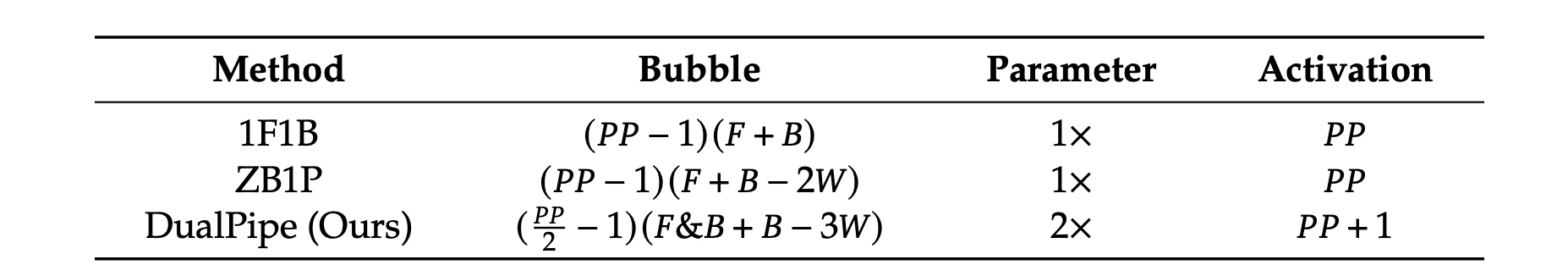
3.2 跨节点高效的all-to-all通信
跨节点的GPU通过IB互联,机内的GPU通过NVLink进行互联,NVLink带宽为160 GB/s,是IB(50 GB/s)的三倍。我们限制一个token最多分发给4个node, 减少IB的流量。当一个token路由策略确定后,先通过IB发给其它结点相同index位置的GPU卡, 传好以后会同时使用NVLink将token传给目标专家。IB与NVLink实现了充分的掩盖,每个token平均一个node选择3.2个expert专家,同时对于NVLink没有带来额外的开销。DeepSeek-V3实际中只选了8个专家,最多可扩到13个专家(4节点 x 3.2 专家/每节点)。20个SMs就够充分使用IB与NVLink带宽。
另外使用了warp特化技术(warp specialization technique),20个SMs切分为10个channel.
在dispatch阶段,(1)IB sending (2)IB-to-NVLink forwarding (3)NVLink
receiving由不同的warp进行处理。warp数会根据通信负载动态调整。同样在combine阶段,
(1)NVLink sending (2)NVLink-to-IB forwardingt and accumulation (3)IB
receiving and
accumulation也会由warp来处理。dispatch与combine的kernel会跟计算流相互掩盖。使用自定义PTX
(Parallel Thread Execution)指令和自动调整通信chunk大小,减少L2
cache使用。
3.3 显存节省
- 重计算RMSNorm与MLA的上映射矩阵
- 模型效果评估中的Exponential Moving Average(EMA)计算放在CPU上
- 多token预测中Embedding与Output Head共享权重
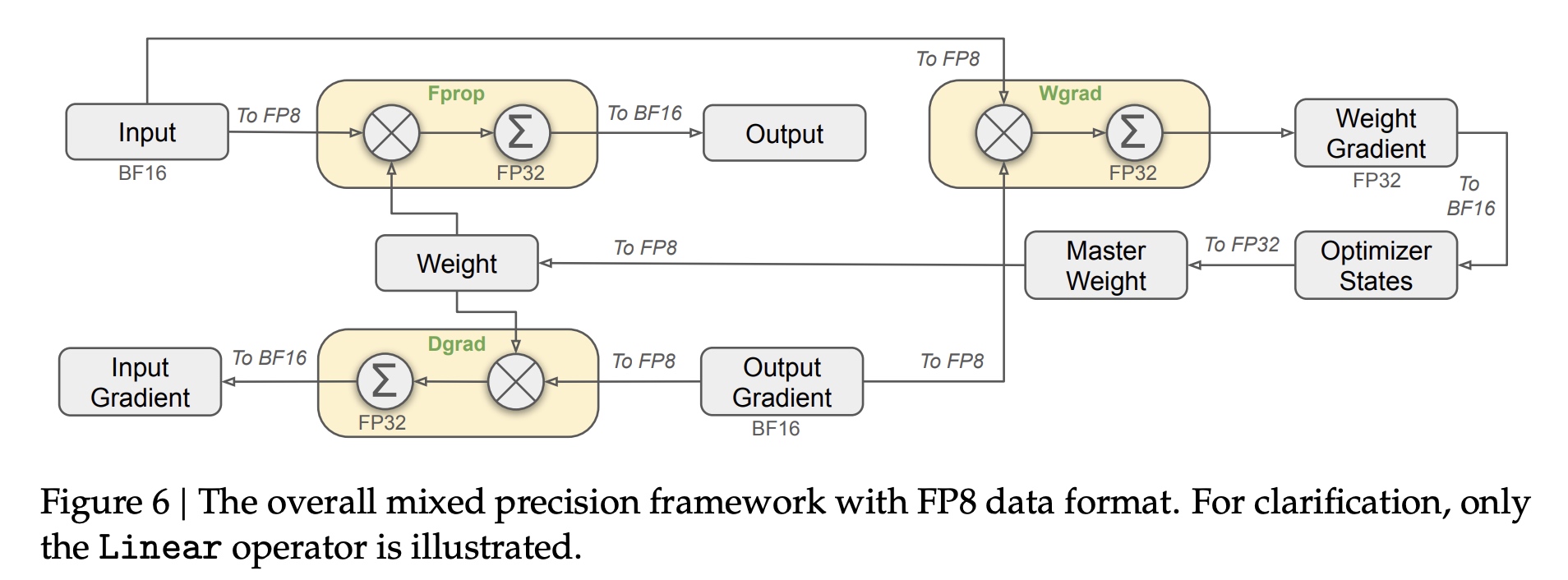
3.4 FP8混合精度训练
在加速过程中大部分计算kernel像GEMM使用FP8来进行计算,输入是FP8类型,输出是BF16或FP32类型。图中黄色Linear层都是FP8计算,Fprop是前向计算,Dgrad是反向激活梯度计算,Wgrad是反向weight梯度计算。另外FP8 Wgrad的激活结果会被存起来用于反向计算。
以下的OP仍使用BF16或FP32类型 * embedding module * output head * MoE gating modules * normalization * attention
3.5 量化与乘法精度提升
3.5.1 细粒度量化方法
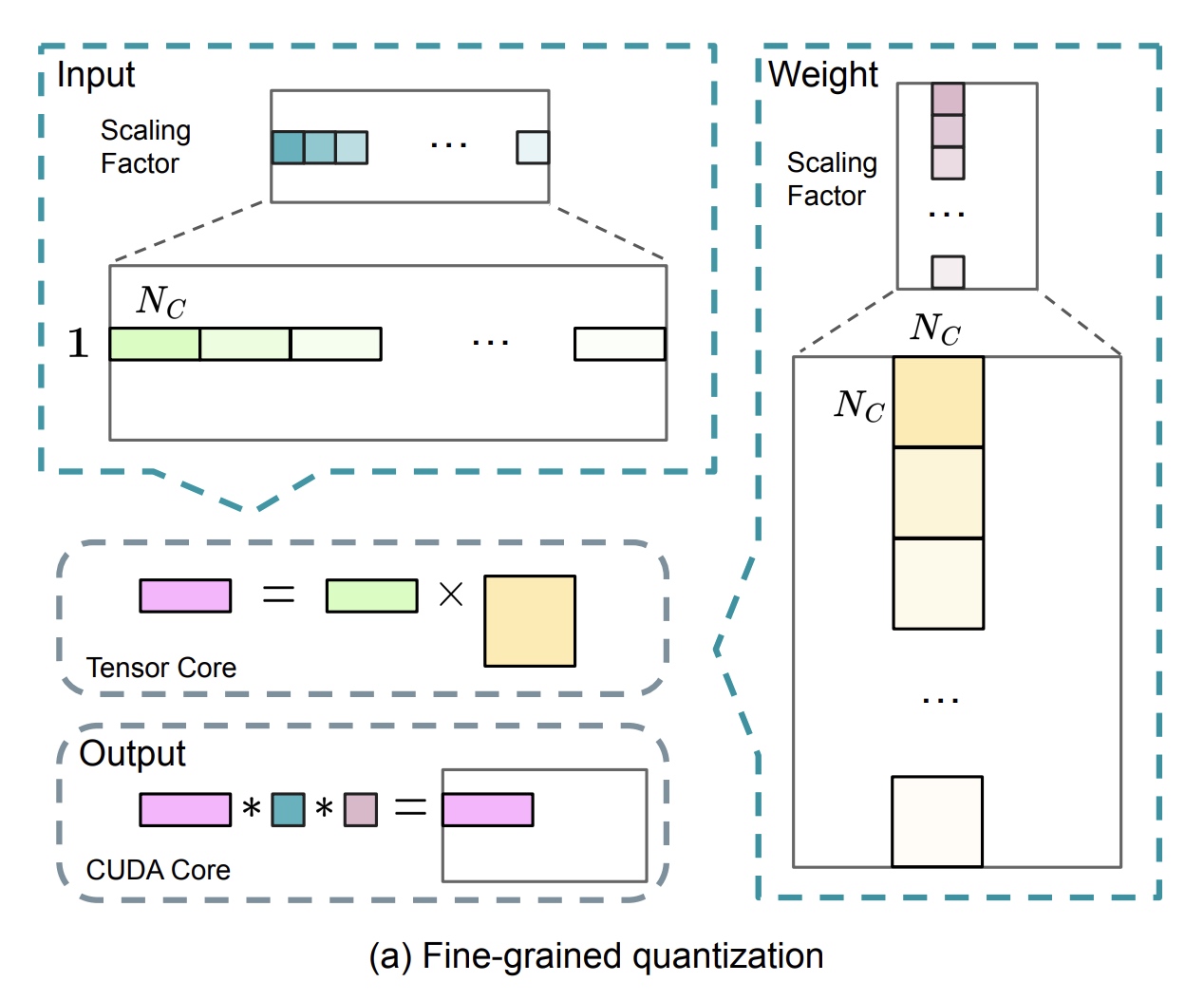
通常量化的方法是把输入最大绝对值scale到FP8表示的最大可表示值,这种量化方法对于激活值中的异常点特别敏感,从而降低了量化的精度。为了解决这个问题,提出了细粒度量化的方法,如下图。对于激活值来说,按 \(1 \times 128\) tile分组(每个token,每128个channel一组);对于权重来说,按 \(128 \times 128\) tile分组(每128输入channel,每128输出channel一组).
当前细粒度量化策略与【Microscaling Data Formats for
Deep Learning】思路一致,同时下一代Blackwell
GPU也已经支持在小粒度量化上支持microscaling formats。
3.5.2 累积的精度提升
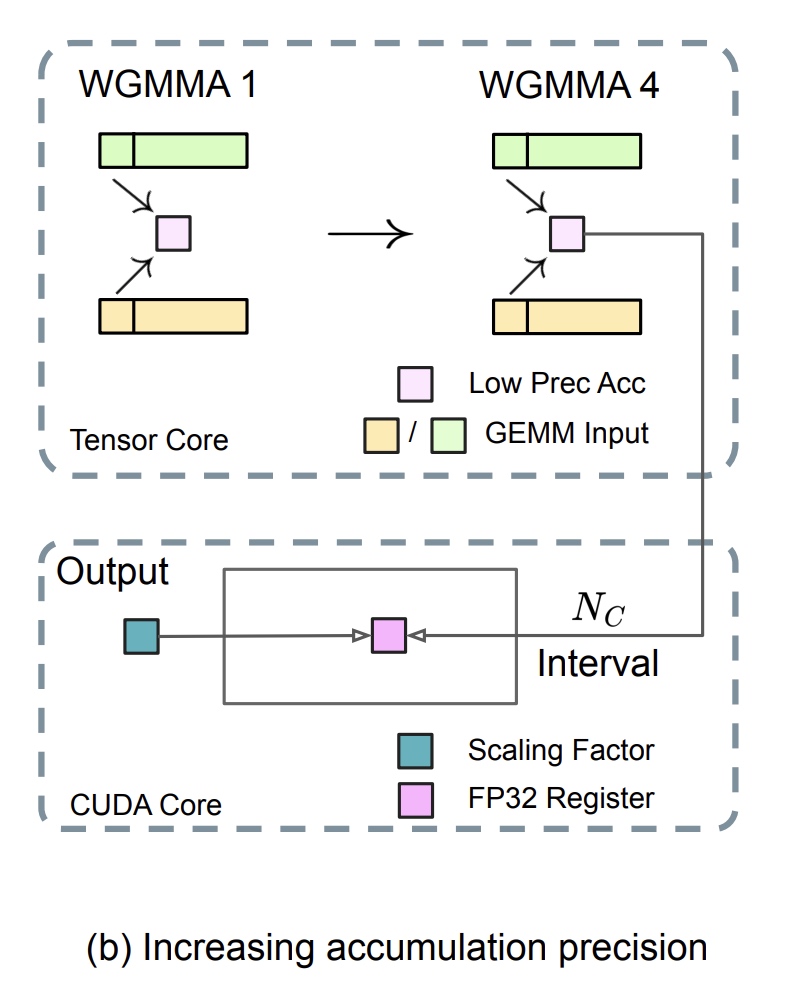
GEMM算子经常存在下溢风险,算子精度很大程度上依赖高精度类型的累加,常为FP32类型。实验观察到在NVIDIA H800 GPU上,FP8 GEMM的累积精度仅能保持大约14位,这明显低于FP32的累积精度。当矩阵内部维度K较大时,这个问题将变得更加明显,一个典型场景是batch size和模型width都变大时会出现这种问题。实验中K=4096时Tensor Cores结果最大相对误差能到2%。
为了解决这个问题采用了CUDA Cores类型提升的方法(NVIDIA/cutlass), 如下图所示,MMA (Matrix Multiply-Accumulate)在Tensor Core上中间interval结果累加使用有限的位宽,当达到了最小累积阈值 \(N_C\) 时再使用全量的FP32累加。细粒度的量化沿内部维度K进行,为每个group分组产生一个scale系数。
这样的改动还降低了WGMMA(Warpgroup-level Matrix Multiply-Accumulate)指令的出问题频率。对于H800架构,两个WGMMA可以并行,一个执行promotion操作,一个执行MMA操作。实验中当 \(N_G=128\) 时,相当于4个 \(WGMMAs\). 最小累积阈值显著提升了精度。
3.5.3 减少指数位
与先前工作采用的混合FP8格式进行对比,后者在Fprop中使用E4M3(4位指数和3位尾数),在Dgrad和Wgrad中使用E5M2(5位指数和2位尾数),我们在所有张量上采用E4M3格式以获得更高的精度。我们将这种方法的可行性归因于我们的细粒度量化策略,即tile和block级别的缩放。通过对较小的元素组进行操作,我们的方法有效地在这些分组元素之间共享指数位,从而减轻了有限动态范围的影响。
3.5.4 在线量化
延迟量化被应用到了tensor感知量化框架中【TransformerEngine】,做法上会保存历史上最大绝对值用于infer。为了简化框架,我们基于每 \(1 \times 128\) tile或者 \(128 \times 128\) block来计算最大绝对值。
3.6 低精度的存储与通信
低精度优化器状态:使用BF16类型代替FP32来保存AdamW的第一和第二moments,表现没有明显下降;master weight和gradient梯度累加还是使用FP32来进行计算。
低精度的激活值:如图中Wgrad操作是按FP8来进行计算的,为了减少显存开销,FP8格式的activation会cache住用于Linear反向的计算。有个别情况要单独考虑:
- 在attention算子计算后的Linear算子的输入:对精度影响大,这里对这些中间激活数据使用 \(E5M6\) 数据类型。激活值会在反向时从 \(1 \times 128\) tile转为 \(128 \times 1\) tile。
- MoE中SwiGLU的输入:这里缓存了SwiGLU算子的输入,在反向时进行了recompute重计算。使用FP8存这里的激活值。
低精度的通信:将MoE中上映射操作(
up-projections)前的激活转为FP8格式,然后进行dispatch操作,跟FP8 Fprop适配。类似attention后的Linear的输入,激活的缩放因子是2的整数次幂;在MoE中下映射操作(down-projections)前的梯度激活也是相同策略。对于前向和反向的combine模块中,保持使用bf16类型来进行计算。
最终模型评估效果对比如下: 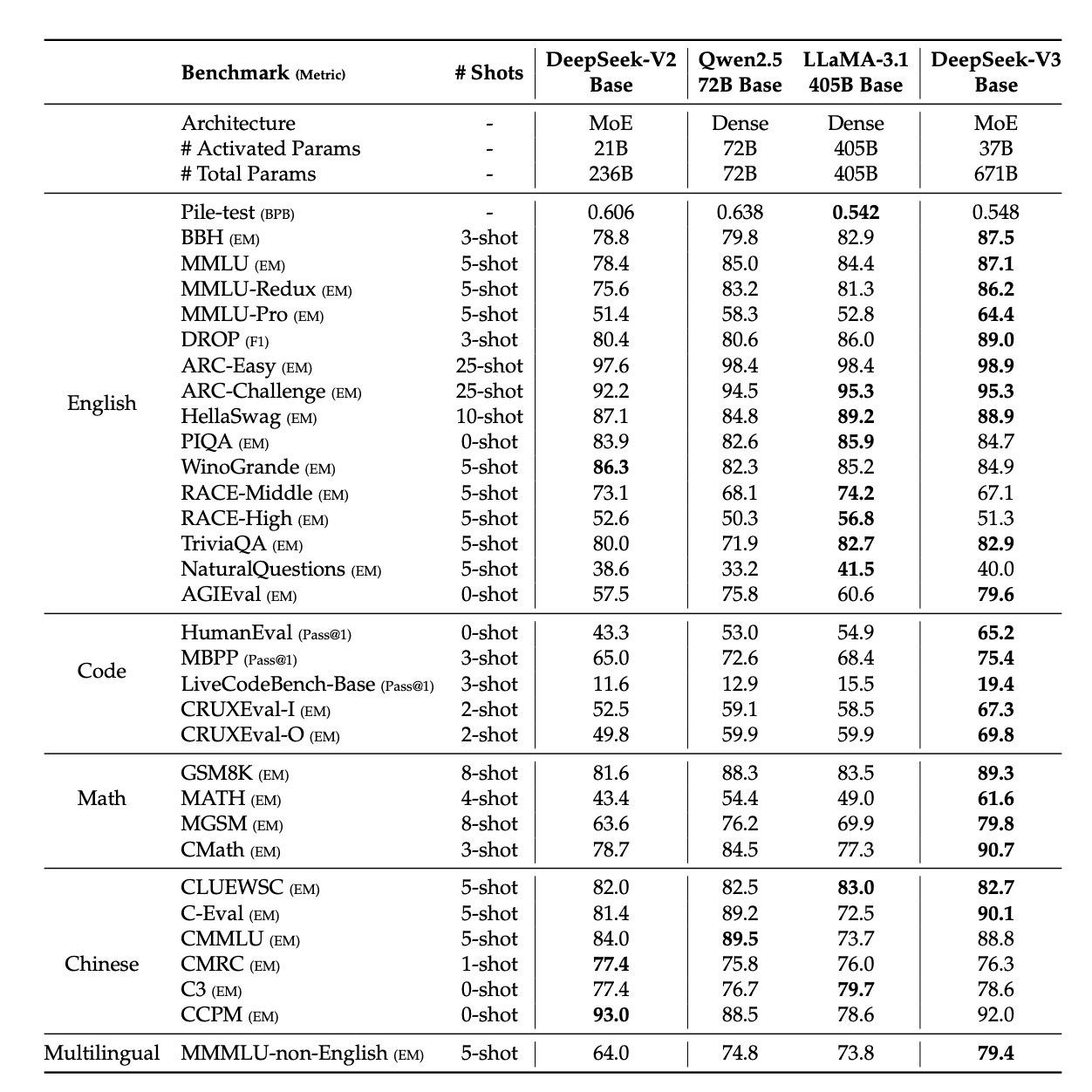
4. 对硬件设计的建议
4.1 通信设计
当前通信原语实现是基于代价大的SMs(H800 132个SMs中取了20个SMs),会影响计算的吞吐。建议后面有单独的硬件处理这些通信。当前SMs用到的地方有如下几个:
- IB与NVLink之前发送数据
- RDMA不同buffer之间以及input/output buffer之间的数据传输
- all-to-all combine中执行的reduce操作
- 细粒度的显存管理,分块的data传给不同的专家
4.2 硬件设计
- 建议Tensor Cores中使用更高的计算精度,当前只用了最高的14位位宽,为了输出FP32精度的结果,32个FP8×FP8的累加至少要有34-bit精度位。
- 支持Tile和Block级别的量化
- 支持在线量化
- 支持带转置的GEMM操作