DeepSeekMoE论文
1. 简介
之前现存的MoE架构像GShard的实现上是在Transformer中的FFN层替换为MoE层,训练时从 \(N\) 个专家中选出 \(top-K\) 个专家进行训练。这类MoE架构往往面临两类问题:(1)知识混合,架构中专家数是有限的(8个/16个),每个token会分发给不同的专家有可能会让专家涉及多样的知识, 在同一时刻很难被同时用到; (2)知识冗余,每个token分成不同专家处理时会涉及相同的知识,所以不同专家在参数中可能会学到相同的知识内容,产生冗余。
对于 \(DeepSeekMoE\) 可以采用了两个原则来实现最大限度的专家特化(即术业有专攻,不同专家的知识越少交叉越好),具体做法:(1)把专家细粒度拆分为 \(mN\) 个,然后使用时激活其中的 \(mK\) 个; (2)将其中的 \(K_s\) 个专家隔离出来共享,用于获取公共知识,减少专家冗余。DeepSeekMoE 2B表现跟GShard 2.9B可比,后者有1.5倍专家参数和计算量;DeepSeekMoE 16B跟LLaMA2 7B可比,计算量减少了40%;DeepSeekMoE 145B可与DeepSeek 67B相比,只用了28.5%的计算量(甚至更少到18.2%计算量)
2. 传统的MoE介绍
先是Transformer的回顾,以下是Transformer的计算公式,其中Transformer总共有
L 层TransformerLayer,\(T\) 表示sequence_length, \(l\) 表示第 \(l\) 个TransformerLayer,\(h_t^l\) 表示第 \(t\) 个token在第 \(l\) 层TransformerLayer的输出,\(u_t^l\) 表示第 \(t\) 个token在第 \(l\) 层 Self-Attention
的输出。
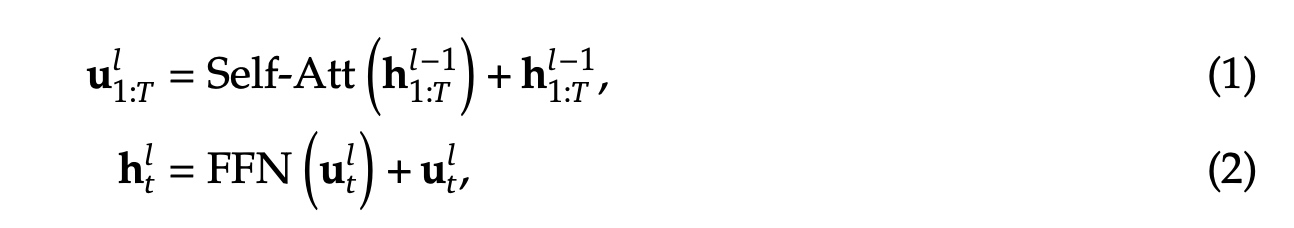
接着是之前MoE的结构,对于FFN层的选择增加了门控网络,\(N\) 表示专家的总个数;\(FFN_i\) 表示第 \(i\) 个专家的FFN网络输出;\(g_{i,t}\) 表示第 \(t\) 个token关于第 \(i\) 个专家的门控权重值,值是稀疏的;\(s_{i,t}\) 表示token与对应专家的亲和度(affinity);\(Topk(·, 𝐾)\) 表示计算完第 \(t\) 个token与所有专家亲和度(affinity)后选出来的前 \(K\) 高的值,其余都设为了0;\(e_i^l\) 表示第 \(l\) 层中第 \(𝑖\) 个专家的中心度
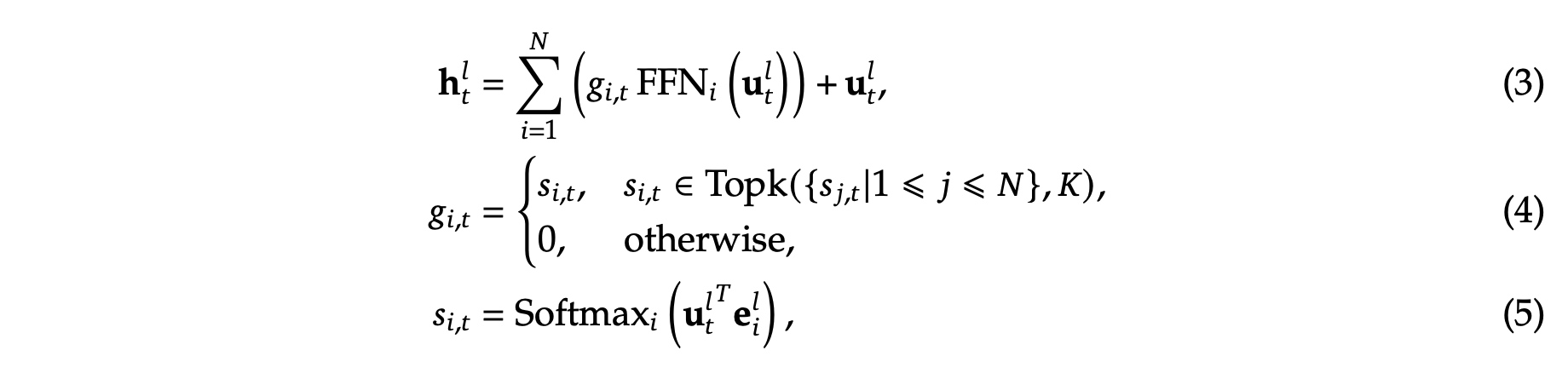
3. DeepSeek-Moe
3.1 专家改动
DeepSeek-Moe跟之前架构相比策略有两点改动:细粒度专家拆分和共享专家隔离。
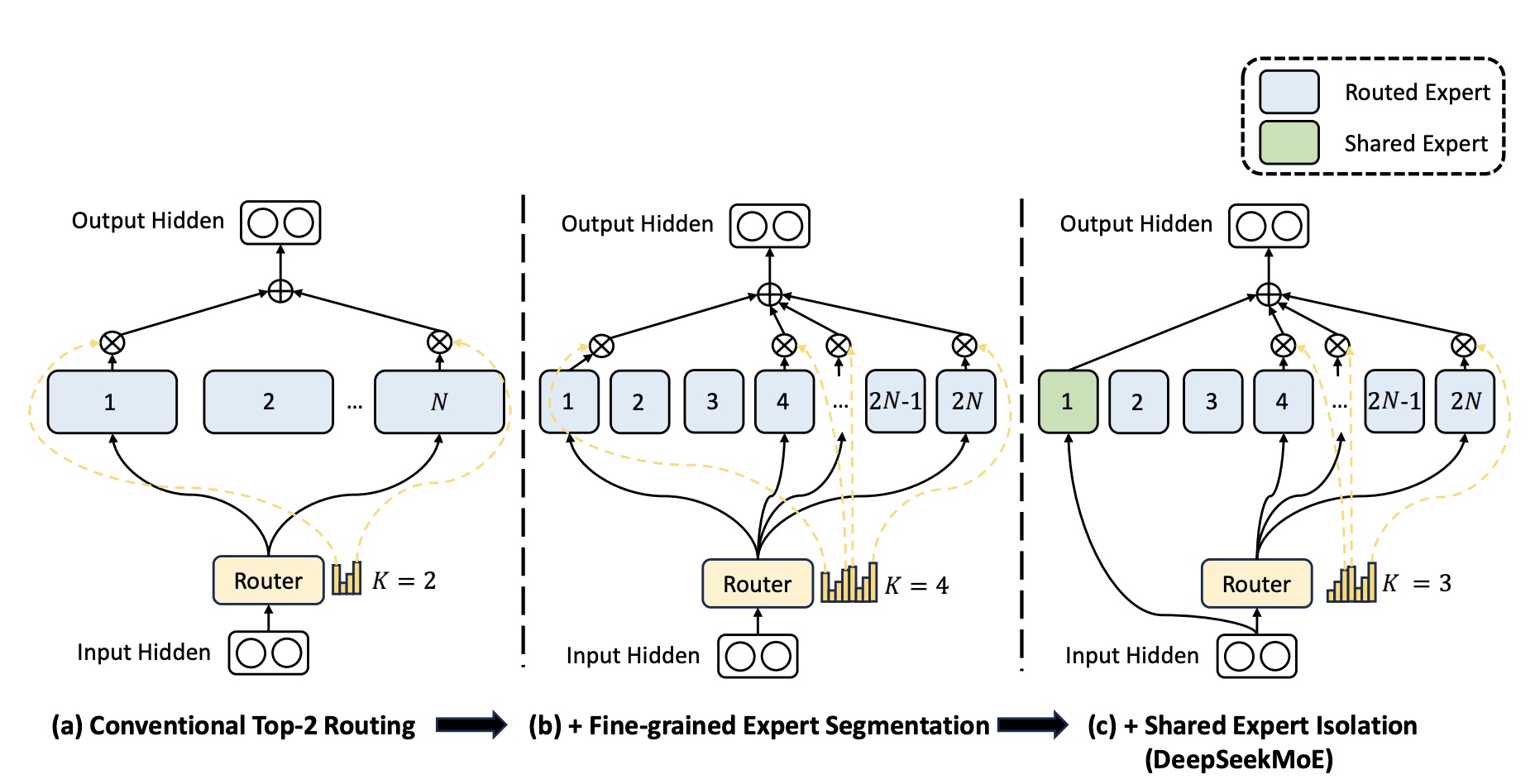 图(a)中表示常见MoE的Top-2路由策略;
图(b)表示细粒度拆分expert的策略;图(c)表示结合了共享expert的策略。
图(a)中表示常见MoE的Top-2路由策略;
图(b)表示细粒度拆分expert的策略;图(c)表示结合了共享expert的策略。
- 细粒度专家拆分:在图(a)基础上把每一个专家FFN层进行进一步的拆分成 \(m\) 份小的FFN层,每一个小的FFN隐层的维度变为原来的 \(\frac{1}{m}\) . 同时激活的专家数量对应增加为原来的 \(m\) 倍,保持了计算量与之前一样,参考图(b)。对应公式如下,\(mN\) 表示细粒度专家个数,\(mK\) 表示门控网络输出的非零值的个数。例如:当N=16时,采用topK-2策略选专家时会有 \((^{16}_2)=120\) 种组合;如果一个专家被拆为4个小的话,会产生 \((^{64}_8)=44261653\) 种组合。
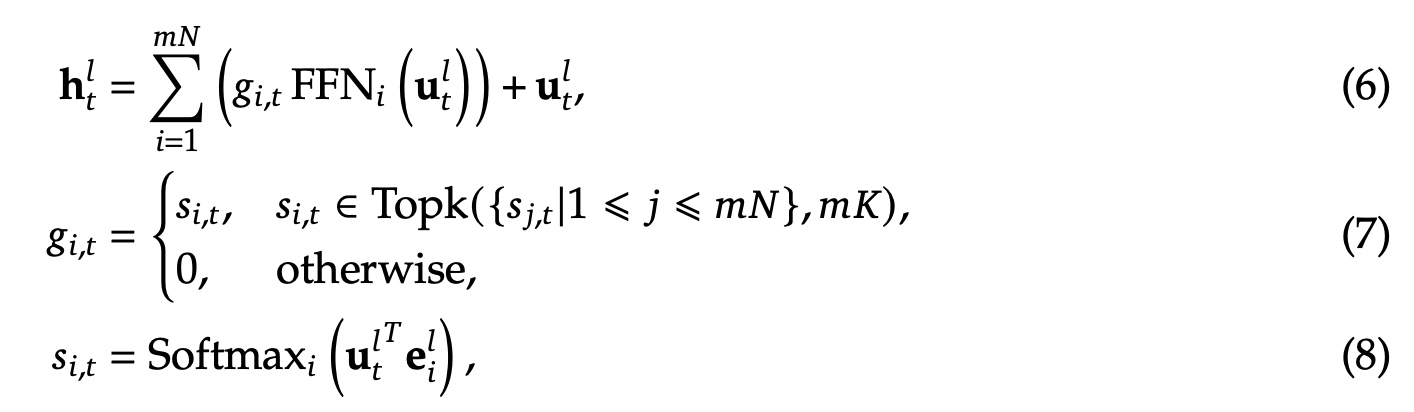
- 共享专家隔离,为了从变化的上下文中捕获公共的知识,如图(c)所示,会从原有的专家中隔离出来 \(K_s\) 个专家做为共享专家,对应公式变为如下,\(K_s\) 表示共享专家个数,\(mN−K_s\) 表示总的路由专家个数,\(mK-K_s\) 非零的门控值个数。
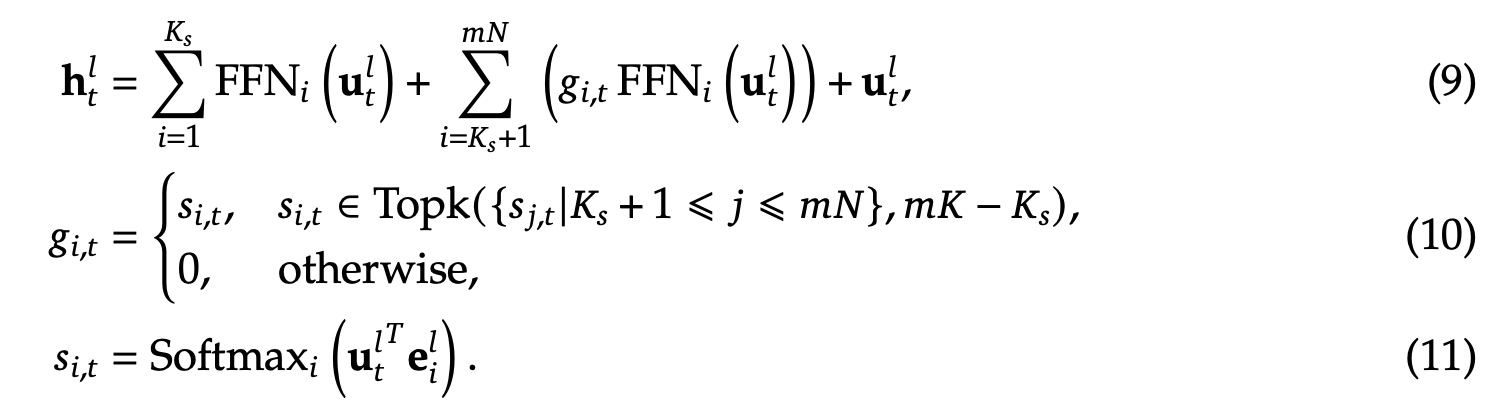
3.2 负载均衡改动
自动学习的负载均衡策略会遇到两个问题,一个是模型经常只会选固定的一部分专家来进行训练,导致没选上的专家训练不足;第二个是专家会分布存在多设备(卡)上,这样负载均衡会成为计算的瓶颈。
- 专家级别的负载均衡loss,其中 \(N'\) 表示 \((𝑚𝑁−𝐾_s)\) , \(K'\) 表示 \(𝑚𝐾−K_s\) , \(\alpha_1\) 是专家级别负载均衡的超参系数

- 设备级别的负载均衡loss,其中 \(\alpha_2\) 是负载均衡超参系数,所有的专家被分为了 \(D\) 组 \({\varepsilon_1, \varepsilon_2, ..., \varepsilon_D}\) , \(f'_i\) 表示按设备粒度统计的 \(f_j\) 之和。
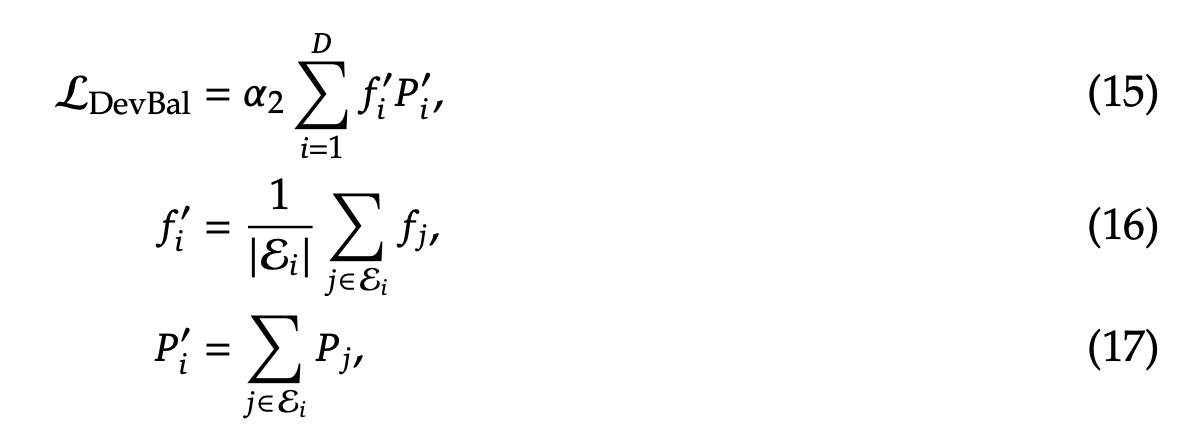
3.3 结果
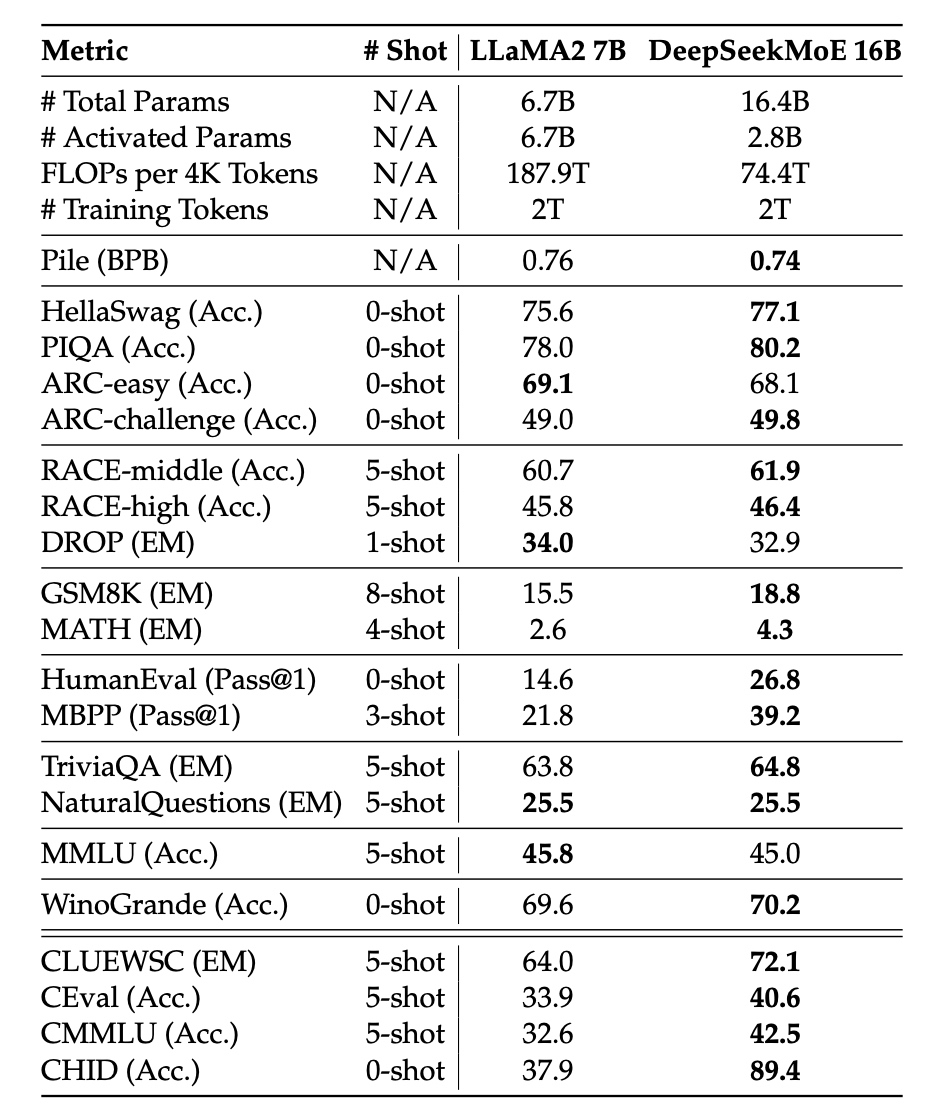
DeepSeekMoE-16B与LLaMA2-7B相比,推理速度快了2.5倍,同时只用了39.6%的算力,在多个评测上效果更好